2018
项目情况
- 项目介绍
JavaSE
集合
集合概述
list与set的异同
hashtable与hashmap异同
以上三点可以从下图简要分析(集合总结2.png):
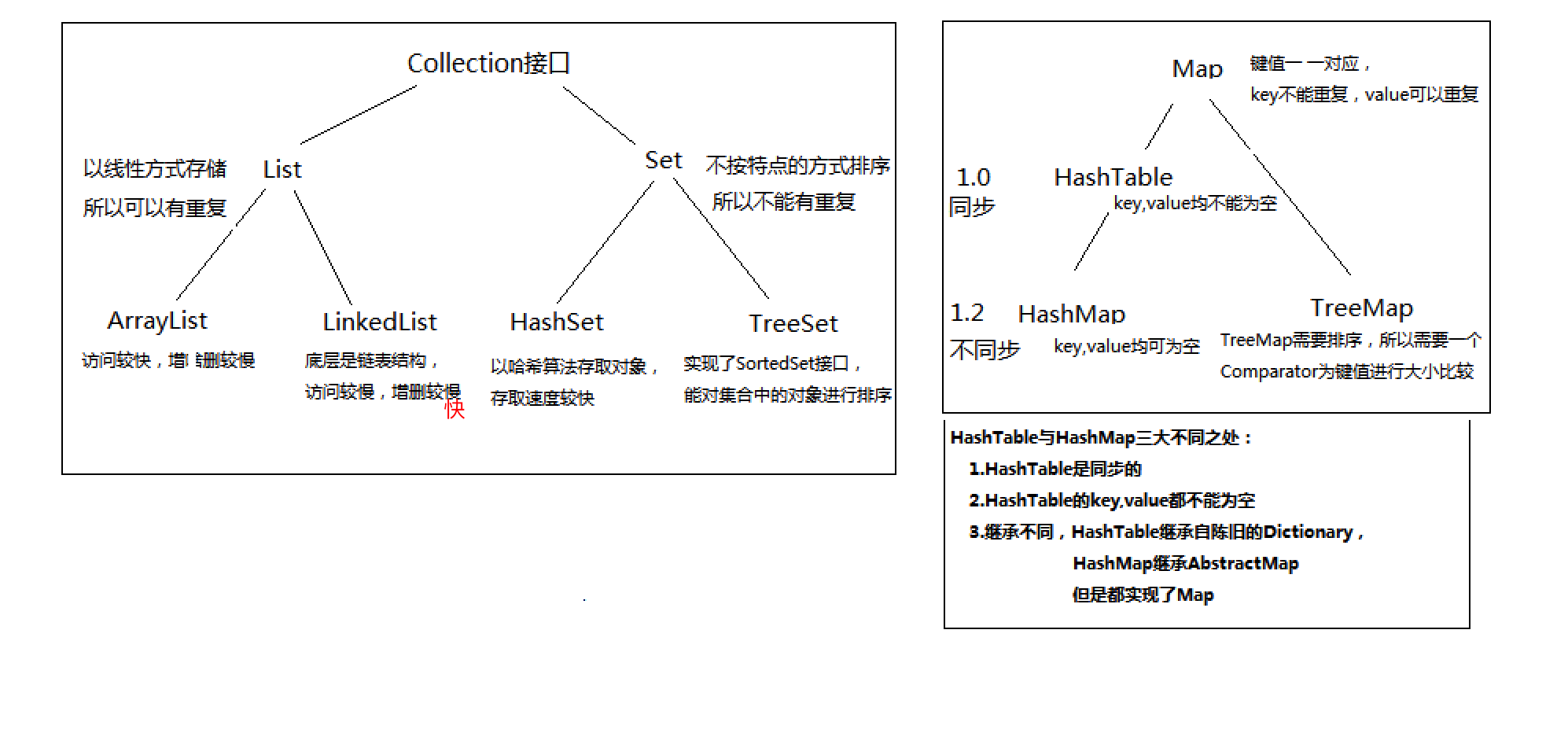
map的key不能重复,value可以重复
JVM
JVM
JVM是Java Virtual Machine(Java虚拟机)的缩写,
JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。
Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。
JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
JVM在执行字节码时,实际上最终还是把字节码解释成具体平台上的机器指令执行。
JVM调优
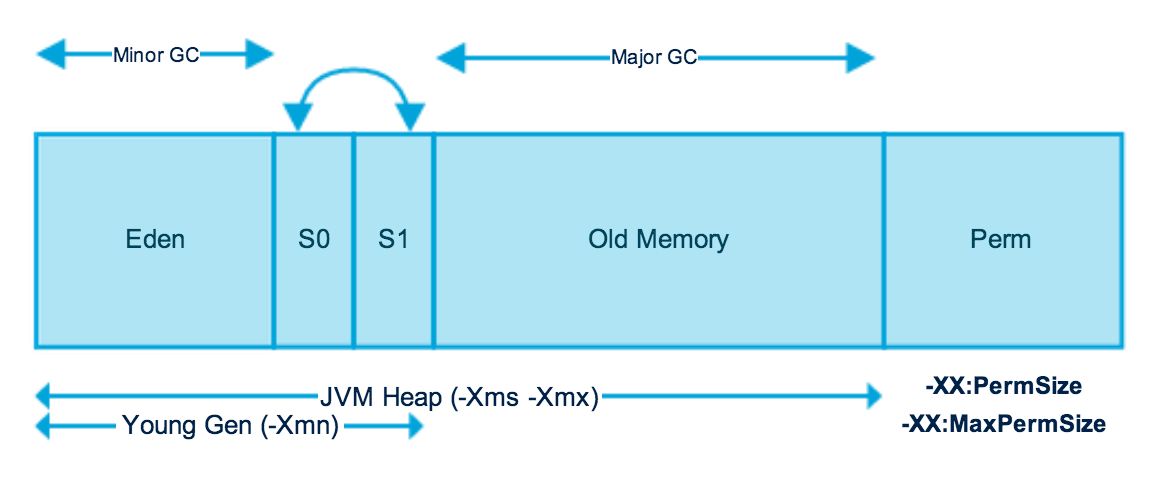
JVM三大性能调优参数:–Xmx -Xms –Xss –Xmx -Xms是对堆的性能调优参数,一般两个设置是一样的, 如果不一样,当Heap(堆)不够用,会发生内存抖动。一般都调大这两个参数,并且两个大小一样。 ---------------------------------------------------------------------------------------------- -Xss是对每一个线程栈的性能调优参数,影响堆栈调用的深度。是指设定每个线程的堆栈大小。这个就要依据你的程序,看一个线程大约需要占用多少内存,可能会有多少线程同时运行等。 -Xmx:代表最大堆。是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多的内存,超出了这个设置值,就会抛出OutOfMemory异常。 -Xms:代表最小堆(初始堆大小)。是指设定程序启动时占用内存大小。一般来讲,大点,程序会启动的快一点,但是也可能会导致机器暂时间变慢。 -Xmn:代表新生代(Young Gen)。 上三个参数的设置都是默认以Byte为单位的,也可以在数字后面添加[k/K]或者[m/M]来表示KB或者MB。而且,超过机器本身的内存大小也是不可以的,否则就等着机器变慢而不是程序变慢了。jvm调优总结:
借助于示例理解:
对于JVM内存配置参数: -Xmx10240m -Xms10240m -Xmn5120m -XXSurvivorRatio=3 其最小内存值和Survivor区总大小分别是() 10240m,2048m --------------------------------------解析---------------------------------------------------- -Xmx10240m:代表最大堆 -Xms10240m:代表最小堆(初始堆大小) -Xmn5120m: 代表新生代(Young Gen) -XXSurvivorRatio=3:代表Eden:Survivor = 3 根据Generation-Collection算法(目前大部分JVM采用的算法),一般根据对象的生存周期将堆内存分为若干不同的区域, 一般情况将新生代分为Eden+两块Survivor; 计算Survivor大小, Eden:Survivor = 3,总大小为5120,3x+x+x=5120 x=1024 所以,2x=1024*2=2048,即Survivor区总大小是2048, -Xms初始堆大小,即最小内存值为10240m (ps:新生代大部分要回收,采用Copying算法,快! 老年代 大部分不需要回收,采用Mark-Compact算法)JVM调优相关1.png

https://www.nowcoder.com/questionTerminal/970cdaaa4a114cbf9fef82213a7dabca
多线程
线程和进程
1.进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同
2.进程中包含线程
3.举例:
开个QQ,开了一个进程;开了迅雷,开了一个进程。
在QQ的这个进程里,传输文字开一个线程、传输语音开了一个线程、弹出对话框又开了一个线程。线程创建方式
1.继承Thread类
class MyThread extends Thread{ ...... @Override public void run(){ ...... } } MyThread mt = new MyThread();//创建线程 mt.start();//启动线程2.实现Runnable接口
class MyThread implements Runnable{ ...... @Override public void run(){ ...... } } MyThread mt = new MyThread(); Thread td = new Thread(mt);//创建线程 td.start();//启动线程对比总结
无论用哪种方法,都要new一个Thread类对象,用Thread类的start方法来启动线程。
线程生命周期(线程生命周期2.png)
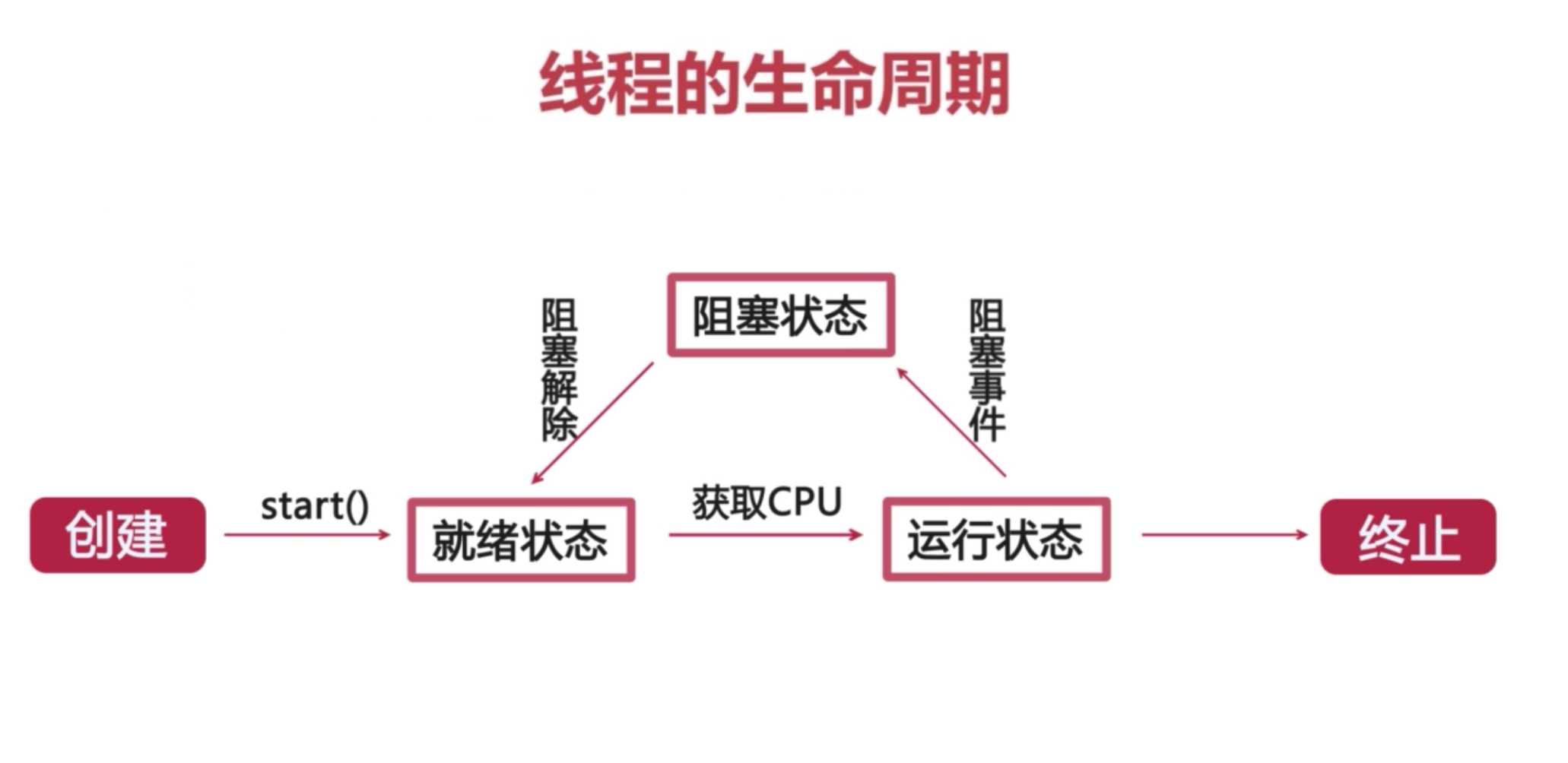
线程各个状态
就绪状态
创建线程对象后,调用了线程的start()方法(此时线程只是进入了线程队列,等待获取CPU服务(cpu可能正在执行其他程序),具备运行条件,但是并不一定已经开始运行了)运行状态
处于就绪状态的线程,一旦线程获取到CPU的服务之后,就进入到了运行状态,开始执行run()方法里面的逻辑。终止
线程的run()方法执行完毕,或者人为线程调用了stop()方法(该做法已经被淘汰),线程便进入终止状态。阻塞
一个正在执行的线程在某些情况下,由于某种原因而暂时让出了CPU资源,暂停了自己的执行,便进入了阻塞状态,如调用 sleep()方法。JDK
JDK7和JDK8的异同(JDK8的新特性)
框架部分
springmvc的单例模式
即:spring MVC中的controller是单例模式,但是是多线程,各个线程之间不影响!
设置为多例模式:@Scope(“prototype”)
@RestController @RequestMapping(value = "hello") @Scope("prototype") public class HelloController {mybatis与hibernate异同
Spring的AOP与IOC
spring是J2EE应用程序的开源框架,是轻量级的IoC和AOP的容器框架,可以单独使用,也可以和其他框架组合使用AOP:
java面向对象思想的拓展,将系统中非核心的业务提取出来,进行单独处理。比如事务、日志和安全等体现java的灵活。 spring中面向切面的实现有两种方式,一种是动态代理,一种是CGLIB,动态代理必须要提供接口,而CGLIB实现是继承。 **关于IoC和DI**IOC与DI:
1)(IOC)控制反转:组件**依赖关系**的创建和管理置于spring容器,由容器控制,而不是由代码直接控制,将控制权转向了容器。 2)(DI)依赖注入:组件之间的依赖关系由容器在运行期决定 ,由容器动态的将某种依赖关系注入到组件之中,实现的程序的解耦。 spring中有三种注入方式,一种是set注入,一种是接口注入,另一种是构造方法注入。 IoC是什么 之●为何是反转,哪些方面反转了: 有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转; 而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象, 对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。spring websocket api
- Spring 4.0的websocket的支持
SSM概述(SSM概述.png):

数据库部分
索引

servlet与CGI
servlet与CGI(Common Gateway Interface 公共网关接口)
Servlet的生命周期分为5个阶段:加载、创建、初始化、处理客户请求、卸载。 (1)加载:容器通过类加载器使用servlet类对应的文件加载servlet (2)创建:通过调用servlet构造函数创建一个servlet对象 (3)初始化:调用init方法初始化 (4)处理客户请求:每当有一个客户请求,容器会创建一个线程来处理客户请求 (5)卸载:调用destroy方法让servlet自己释放其占用的资源JSP九大内置对象
JSP九大内置对象
区别
String:适用于少量的字符串操作的情况 StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况 StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况从JVM角度分析String慢的原因
那么JVM就会像上面说的那样,不断的创建、回收对象来进行这个操作了。速度就会很慢。StringBuffer与StringBuilder
StringBuilder是线程不安全的,而StringBuffer是线程安全的 StringBuffer JDK1.0出现 StringBuilder JDK1.5出现mybatis缓存
一级缓存和二级缓存
mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来, 当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户, 不需要再进行一次数据库查询了。 MyBatis会在一次会话的SqlSession对象中创建一个本地缓存(local cache), 对于每一次查询,都会尝试*根据查询的条件*去本地缓存中查找是否在缓存中,如果在缓存中, 就直接从缓存中取出,然后返回给用户;否则,从数据库读取数据,将查询结果存入缓存并返回给用户。 一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象, 在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。 不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。 一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句, 第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。 当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。Mybatis默认开启一级缓存。 二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句, 多个SqlSession去操作数据库得到数据会存在二级缓存区域,多个SqlSession可以共用二级缓存, 二级缓存是跨SqlSession的。 二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace, 不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句, 第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。 Mybatis默认没有开启二级缓存需要在setting全局参数中配置开启二级缓存。参考
https://www.cnblogs.com/little-fly/p/6251451.html
http://www.jb51.net/article/116961.htm
2019
spring中使用了哪些设计模式?
JDK动态代理和CGLIB动态代理
https://juejin.im/post/5c3e9c37f265da61263862f1
https://juejin.im/post/5bbff7daf265da0aef4e330c
2020
1.Java 的类加载器相关
1.Java 的类加载器的种类都有哪些?
1、根类加载器(Bootstrap) --C++写的 ,看不到源码 2、扩展类加载器(Extension) --加载位置 :jre\lib\ext 中 3、系统(应用)类加载器(System\App) --加载位置 :classpath 中 4、自定义加载器(必须继承 ClassLoader)2.类什么时候被初始化?
1)创建类的实例,也就是 new 一个对象 2)访问某个类或接口的静态变量,或者对该静态变量赋值 3)调用类的静态方法 4)反射(Class.forName("com.lyj.load")) 5)初始化一个类的子类(会首先初始化子类的父类) 6)JVM 启动时标明的启动类,即文件名和类名相同的那个类 只有这 6 中情况才会导致类的类的初始化。 类的初始化步骤: 1)如果这个类还没有被加载和链接,那先进行加载和链接 2)假如这个类存在直接父类,并且这个类还没有被初始化 (注意:在一个类加载器中,类只能初始化一次),那就初始化直接的父类(不适用于接口) 3)加入类中存在初始化语句(如 static 变量和static 块),那就依次执行这些初始化语句。3.Java 类加载体系之ClassLoader和双亲委托机制
java 是一种类型安全的语言,它有四类称为安全沙箱机制的安全机制来保证语言的安全性, 这四类安全沙箱分别是: 1)类加载体系 2).class 文件检验器 3)内置于 Java 虚拟机(及语言)的安全特性 4)安全管理器及Java API 这里主要讲解类的加载体系: java 程序中的 .java 文件编译完会生成 .class 文件,而 .class 文件 就是通过被称为类加载器的ClassLoader加载的,而 ClassLoder 在加载过程中会 使用“双亲委派机制”来加载 .class 文件,先上图: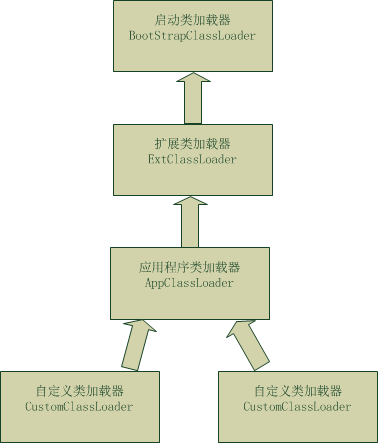
1.BootStrapClassLoader:启动类加载器,该ClassLoader是jvm在启动时创建的, 用于加载 $JAVA_HOME$/jre/lib 下面的类库(或者通过参数-Xbootclasspath指定)。 由于启动类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用, 所以不能直接通过引用进行操作。 2.ExtClassLoader:扩展类加载器,该ClassLoader是在sun.misc.Launcher里 作为一个内部类ExtClassLoader定义的(即 sun.misc.Launcher$ExtClassLoader), ExtClassLoader 会加载 $JAVA_HOME/jre/lib/ext 下的类库 (或者通过参数-Djava.ext.dirs 指定)。 3.AppClassLoader:应用程序类加载器,该ClassLoader同样是在sun.misc.Launcher里 作为一个内部类AppClassLoader 定义的(即 sun.misc.Launcher$AppClassLoader), AppClassLoader 会加载java环境变量CLASSPATH所指定的路径下的类库,而CLASSPATH所指定的路径 可以通过System.getProperty("java.class.path")获取;当然,该变量也可以覆盖, 可以使用参数-cp,例如:java -cp 路径 (可以指定要执行的 class 目录)。 4.CustomClassLoader:自定义类加载器,该ClassLoader 是指我们自定义的ClassLoader, 比如tomcat的StandardClassLoader 属于这一类;当然,大部分情况下使用AppClassLoader 就足够了。
前面谈到了ClassLoader 的几类加载器,而ClassLoader使用双亲委派机制来加载class文件的。ClassLoader的双亲委派机制是这样的(这里先忽略掉自定义类加载器 CustomClassLoader):
1)当AppClassLoader加载一个class时,它首先不会自己去尝试加载这个类,而是把类加载请求委派给父类加载器ExtClassLoader去完成。 2)当ExtClassLoader加载一个class时,它首先也不会自己去尝试加载这个类,而是把类加载请求委派给 BootStrapClassLoader去完成。 3)如果BootStrapClassLoader加载失败(例如在$JAVA_HOME$/jre/lib 里未查找到该class), 会使用ExtClassLoader来尝试加载; 4)若 ExtClassLoader也加载失败,则会使用AppClassLoader来加载,如果AppClassLoader 也加载失败,则会报出异常ClassNotFoundException。下面贴下ClassLoader 的loadClass(String name, boolean resolve)的源码:
protected synchronized Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { // 首先找缓存是否有 class Class c = findLoadedClass(name); if (c == null) { //没有判断有没有父类 try { if (parent != null) { //有的话,用父类递归获取 class c = parent.loadClass(name, false); } else { //没有父类。通过这个方法来加载 c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // 如果还是没有找到,调用 findClass(name)去找这个类 c = findClass(name); } } if (resolve) { resolveClass(c); } return c; } 代码很明朗:首先找缓存(findLoadedClass),没有的话就判断有没有 parent, 有的话就用 parent 来递归的 loadClass,然而 ExtClassLoader 并没有设置 parent, 则会通过 findBootstrapClassOrNull 来加载 class,而findBootstrapClassOrNull 则会通过 JNI 方法”private native Class findBootstrapClass(String name)“来 使用 BootStrapClassLoader 来加载 class。 然后如果parent未找到class,则会调用findClass来加载class,findClass是一个 protected 的空方法,可以覆盖它以便自定义class加载过程。 另外,虽然ClassLoader加载类是使用loadClass方法,但是鼓励用ClassLoader的子类重写 findClass(String),而不是重写 loadClass,这样就不会覆盖了类加载默认的双亲委派机制。4.双亲委派托机制为什么安全
举个例子,ClassLoader加载的class文件来源很多,比如编译器编译生成的class、或者网络下载的字节码。 而一些来源的class 文件是不可靠的,比如我可以自定义一个java.lang.Integer类来覆盖jdk中默认的 Integer类,例如下面这样: package java.lang; public class Integer { public Integer(int value) { System.exit(0); } } 初始化这个Integer 的构造器是会退出JVM,破坏应用程序的正常进行,如果使用双亲委派机制的话 该Integer类永远不会被调用,以为委托BootStrapClassLoader加载后会加载JDK中的Integer类 而不会加载自定义的这个,可以看下下面这测试个用例: public static void main(String... args) { Integer i = new Integer(1); System.err.println(i); } 执行时 JVM 并未在 new Integer(1)时退出,说明未使用自定义的 Integer,于是就保证了安全性。4.mybatis(mapper)调用过程
Mapper方法的执行过程:先获取Mapper对象,该对象是JdbcProxy代理对象。 代理对象回调接口里,会根据Method,执行org.apache.ibatis.session.SqlSession对应的方法, 同时需要完成参数的转化.https://blog.csdn.net/bingospunky/article/details/79220894
https://www.jianshu.com/p/3c56bf3313ce5.hashMap
6.redis存储方式
Redis是一个由ANSI C语言编写,性能优秀、支持网络、可持久化的K-K内存数据库, 并提供多种语言的API。它常用的类型主要是 String、List、Hash、Set、ZSet 这5种。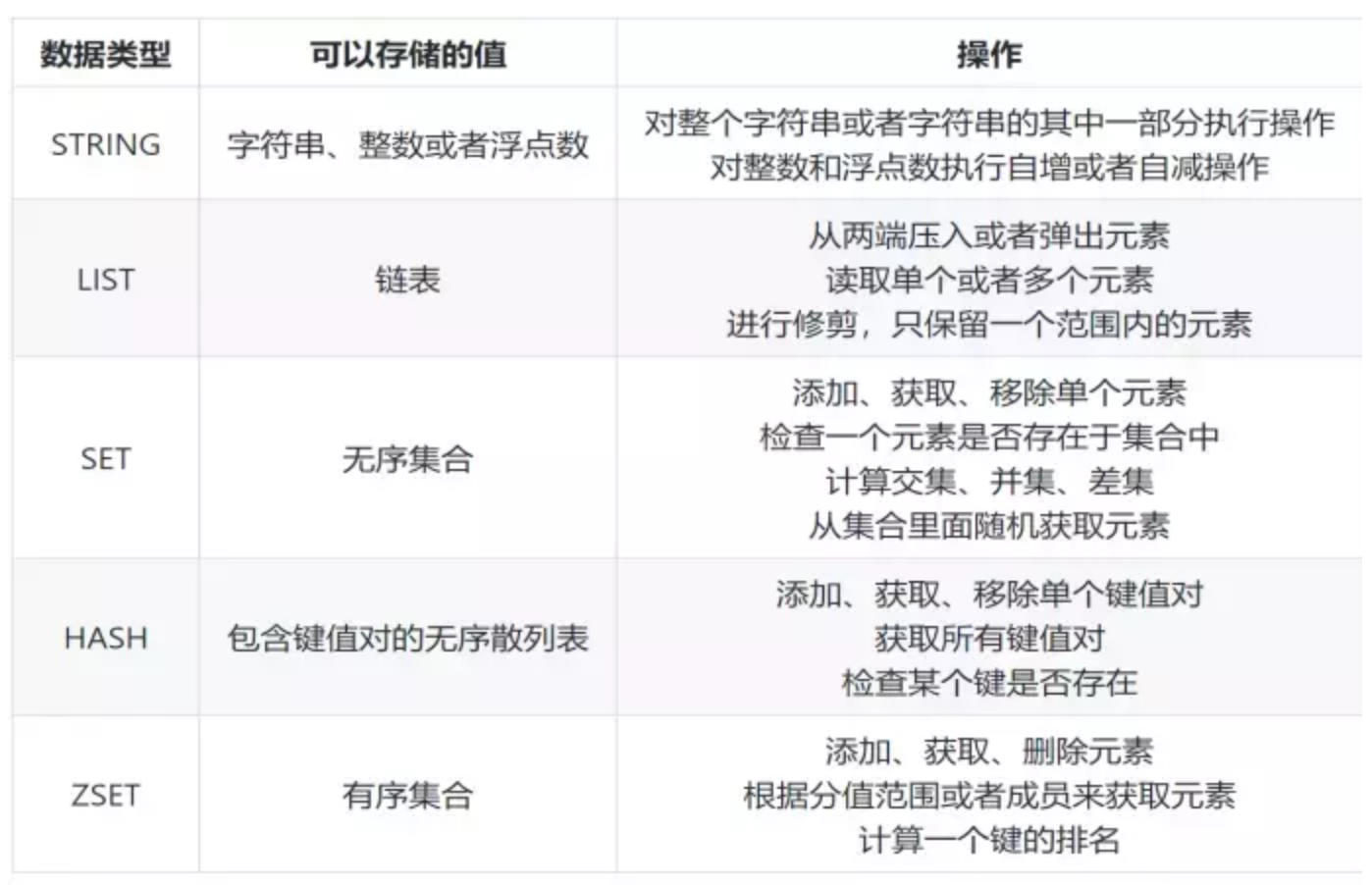
Redis在互联网公司一般有以下应用: String:缓存、限流、计数器、分布式锁、分布式Session Hash:存储用户信息、用户主页访问量、组合查询 List:微博关注人时间轴列表、简单队列 Set:赞、踩、标签、好友关系 Zset:排行榜7.MySQL数据库索引的4大类型及相关的索引创建
1.普通索引 这是最基本的MySQL数据库索引,它没有任何限制。它有以下几种创建方式: a:创建索引: CREATE INDEX indexName ON mytable(username(length)); b:修改表结构: ALTER mytable ADD INDEX [indexName] ON (username(length)) 创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) ); c:删除索引的语法: DROP INDEX [indexName] ON mytable; 2.唯一索引 它与前面的普通索引类似,不同的就是:MySQL数据库索引列的值必须唯一,但允许有空值。 如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式: a:创建索引: CREATE UNIQUE INDEX indexName ON mytable(username(length)) b:修改表结构 ALTER mytable ADD UNIQUE [indexName] ON (username(length)) c:创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) ); 3.主键索引 它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引: CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, PRIMARY KEY(ID) ); 当然也可以用 ALTER 命令。记住:一个表只能有一个主键。 4.组合索引7.ArrayList和LinkedList
ArrayList和LinkedList都是实现了List接口的容器类,用于存储一系列的对象引用。 他们都可以对元素的增删改查进行操作。 ArrayList和LinkedList的大致区别如下: 1.ArrayList是实现了基于 动态数组 的数据结构,LinkedList是基于 链表结构 。 2.对于随机访问的get和set方法,ArrayList要优于LinkedList,因为LinkedList要移动指针。 3.对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。8.查询前10条数据和后10条数据:
select top 10 * from tablename 或者按时间正序or倒序,limit10 select * from aaa where create_time<="2017-03-29 19:30:36" order by create_time desc/asc limit 10 如果按照某个字段排序后,再limit10查询,速度有区别?貌似没区别9.SQL调优,查询调优
10.shiro、springsecurity框架
11.springcloud组件
12.SpringMVC调用流程(8大步骤)
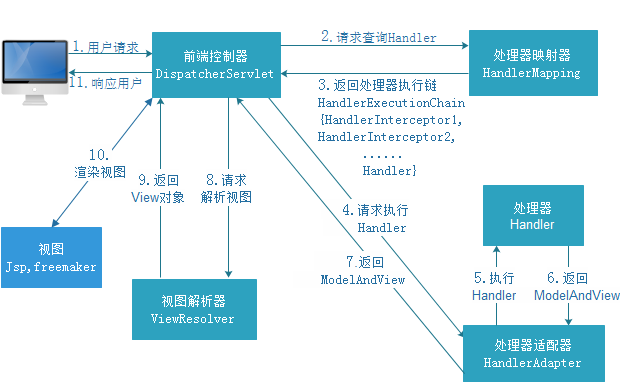
先记住几个概念:
前端控制器 DispatcherServlet
处理器映射器 HandlerMapping
处理器执行链 HandlerExecutionChain
处理器适配器 HandlerAdapter
视图解析器ViewResolver
调用步骤:
1、客户端请求到前端控制器(dispatcherServlet)
2、前端控制器(dispatcherServlet)请求处理器映射器(HandlerMapping),
3、处理器映射器(HandlerMapping)根据url查找相应的处理器(Handler),返回处理器执行链(HandlerExecutionChain)给前端控制器(DispatcherServlet)
4、前端控制器(DispatcherServlet)请求处理器适配器(HandlerAdapter),
5、处理器适配器(HandlerAdapter)执行处理器(Handler),生成ModelAndView,返回ModelAndView给前端控制器(DispatcherServlet)
6、前端控制器(DispatcherServlet)请求视图解析器(ViewResolver)
7、视图解析器(ViewResovler)返回视图对象给前端控制器(DispatcherServlet)
8、最后渲染视图
13.优化Mysql数据库的方法
回答一:
表优化,库优化,sql 优化,引擎优化。分库分表,设置合理字段、合理的字段索引数量,
读写分离,少用多层嵌套子查询,少用分组查询,少用多条件查询,少用模糊查询,查询中少用计算或统计等等。
优化的方式很多
回答二:
mysql 数据库优化从两方面入手。
1.通过优化配置参数
如合适的 innodb 池大小,取消反向解析,合理的连接数,合理的超时时长,合理的相关 cache 等
2.通过操作的优化
如,合理的表结构,合理的索引,合理的查询语录(可通过分析慢查询日志找出可优化的,再通过 explain 去测试语句,找出可优化的点进行优化)。
如果都有优化了还有瓶颈、最后就是分表、分库、扩硬件、主从读写分离
回答三(SQL级别):
创建索引
索引不会包含有 NULL 值的列
一般情况下不鼓励使用 like 操作,如果非使用不可,如何使用也是一个问题。
like “%aaa%” 不会使用索引而 like “aaa%”可以使用索引。
不要在列上进行运算
不使用 NOT IN 和<>操作
14.redis和mysql数据不一致怎么解决
1 如果是 redis cluter 集群
因为 redis cluter 集群采用异步复制,在故障切换的过程中删除操作有可能丢失,所以只是删除缓存操作是有可能 redis mysql 不一致的,需要根据业务做特殊处理。
2 如果是单机 redis
在更新数据的时候先加写锁,然后删除缓存,在加载缓存的时候加读锁,可有避免数据在修改过程中其他线程加载旧数据到 redis
15.Mybatis原理
mybatis 是数据持久层框架,基本原理是:
1.创建 SqlSessionFactoryBuilder 对象,调用 build(inputstream)方法读取并解析配置文件,
返回 SqlSessionFactory 对象
2.由 SqlSessionFactory 创建 SqlSession 对象,没有手动设置的话事务默认开启
3.调用 SqlSession 中的 api,传入 Statement Id 和参数(mybatis dao xml 映射),
内部进行复杂的处理,最后调用 jdbc 执行 SQL 语句,封装结果返回
16.Spring的底层实现原理
SpringIOC 的底层实现原理是:
传统开发方式:Person person = new Person
这种开发方式耦合度太高,不符合 java 编程思想(高内聚,低耦合)。
Spring ioc 就是把对象交给 spring 进行管理,需要的时候就去工厂拿就可以了,实现了低耦合,高内聚。
原理是:
首先加载 xml 配置文件,通过 dom4j 去解析 xml 文件,然后通过工厂模式和反射去创建对象。
Springaop 的实现原理:
aop,面向切面编程,是 Spring 两大核心之一,Springaop 是通过代理的方式实现切面编程的。
主要是以下两种代理方式:
一种是基于 JDK 的动态代理(目标对象实现了接口)
一种是基于 cglib 的动态代理(目标对象没有实现接口)
17.Collection 和 Collections 的区别。
Collection 是集合类的上级接口,继承与他的接口主要有 Set 和 List。
Collections 是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
18.HashMap 工作原理是什么?
回答一:
1.8 之前,hashmap 的数据结构是:数组+链表
1.8 以后,hashmap 的数据结构是:数组+链表+红黑树
1.8 以后,做了很大的改变,使用红黑树,可以大大提高查询效率。
可以深挖一下红黑树的应用。
就其他方面来说,
1.8 插入元素时,使用的是头插法,在插入元素出现 hash 碰撞,会引起红黑树数据结构进行对 node 链表数据的插入。
回答二:
原理是hash表
能快速定位到指定的 key 对应的 value,实现使用的是数组加一个链式结构,
1.8 之前用的是链表,1.8 之后用的是链表加红黑树。
插入数据的基本流程就是计算 k 的 hashcode 然后用这个 hashcode 去和整个数组空间去进行按位于,
得到具体需要放置的数组索引。
然后就是一个比对和放置的过程,对比当前的数据链是否有相同的,没有就放,有就不放。
取出数据规则差不多也是根据 key 的 hashcode 去得到数组索引位,然后比对
19.请解释什么是值传递和引用传递?
值传递是对基本型变量而言的,传递的是该变量的一个副本,改变副本不影响原变量。
引用传递一般是对于对象型变量而言的,传递的是该对象地址的一个副本,并不是原对象本身。
所以对引用对象进行操作会同时改变原对象。
一般认为 Java 内的传递都是值传递。
20.内存溢出和内存泄露区别
内存溢出:
内存溢出就是常见的 OOM,说白了就是申请的内存小了,可能原因 JVM 内存太小,
对象所需内存太大,还有可能就是程序设计问题。解决方式要么修改 jvm 参数,要么修改程序。
内存泄露:
内存泄露就是对象本应该被回收,但是其他地方还在使用它的引用,导致无法释放内存,
引起这种的原因一般是非静态内部类中创建了静态实例,或者是单例对象,因为单例的静态特性,
会使它生命周期和应用的生命周期一样长,如果一个对象已经不需要了,但单例对象还依旧持有该对象的引用,
就会导致不能被正常回收,致使内存泄露。集合容器也可能导致内存泄露,因为集合很大的时候,没有来得及清理,
也会导致内存泄露。避免的最好的方式就是养成良好编码习惯,该销毁的对象要销毁,涉及到上下文的优先考虑全局。
21.请介绍一下 Syncronized 锁,如果用这个关键字修饰一个静态方法,锁住了什么?如果修饰成员方法,锁住了什么?
Synchronized 修饰静态方法以及同步代码块的 Synchronized (类.class)用法锁的是类,
线程想要执行对应同步代码,需要获得类锁。
Synchronized 修饰成员方法,线程获取的是当前调用该方法的对象实例的对象锁。
22.MySQL的四种事务隔离级别
一.事务的基本要素(ACID)
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
二.MySQL事务隔离级别
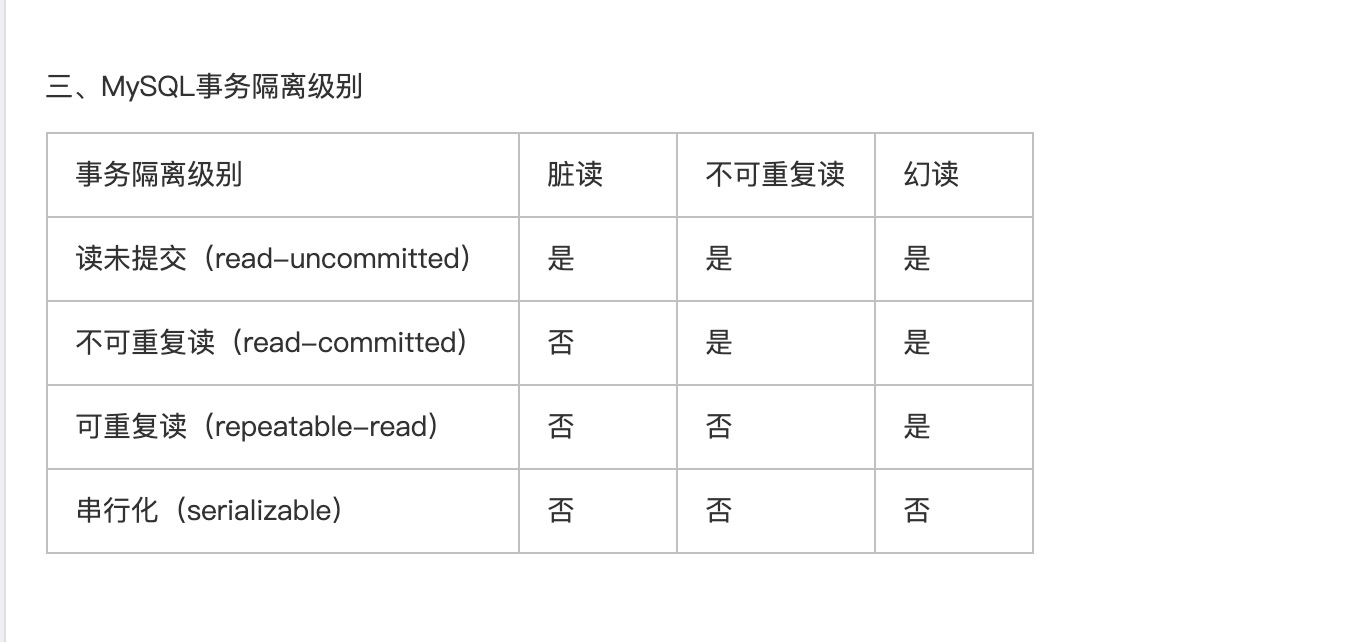
三、事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,
导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,
但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,
就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。
解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
23.spring是如何解决循环依赖问题的
如何理解“依赖”呢,在Spring中有:
构造器循环依赖
field属性注入循环依赖
https://www.cnblogs.com/sun-sun/p/10521334.html
https://www.jianshu.com/p/8bb67ca11831
redis做同步锁
redis分布式加锁解锁
***synchronized处理并发.wmv*** com.imux.wxsell.service包下的RedisLock类: package com.imux.wxsell.service; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.stereotype.Component; import org.springframework.util.StringUtils; /** * redis lock */ @Component @Slf4j public class RedisLock { @Autowired private StringRedisTemplate stringRedisTemplate; /** * 加锁 * * @param key productId - 商品的唯一标志 * @param value 当前时间+超时时间>>>即过期的时刻 * @return */ public boolean lock(String key, String value) { //setIfAbsent >>>>>>>redis的SETNX方法 if (stringRedisTemplate.opsForValue().setIfAbsent(key, value)) {//对应setnx命令 //可以成功设置,也就是key不存在 return true; } //判断锁超时 - 防止原来的操作异常,没有运行解锁操作 防止死锁 String currentValue = stringRedisTemplate.opsForValue().get(key); //如果锁过期 if (!StringUtils.isEmpty(currentValue) && Long.parseLong(currentValue) < System.currentTimeMillis()) {//currentValue不为空且小于当前时间 //获取上一个锁的时间value String oldValue = stringRedisTemplate.opsForValue().getAndSet(key, value);//对应getset,如果key存在 //假设两个线程同时进来,key被占用了。获取的值currentValue=A(get取的旧的值肯定是一样的),两个线程的value都是B,key都是K.锁时间已经过期了。 //而这里面的getAndSet一次只会一个执行,也就是一个执行之后,上一个的value已经变成了B。只有一个线程获取的上一个值会是A,另一个线程拿到的值是B。 if (!StringUtils.isEmpty(oldValue) && oldValue.equals(currentValue)) { //oldValue不为空且oldValue等于currentValue,也就是校验是不是上个对应的商品时间戳,也是防止并发 return true; } } return false; }
/** * 解锁 * * @param key * @param value */ public void unlock(String key, String value) { try { String currentValue = stringRedisTemplate.opsForValue().get(key); if (!StringUtils.isEmpty(currentValue) && currentValue.equals(value)) { stringRedisTemplate.opsForValue().getOperations().delete(key);//删除key } } catch (Exception e) { log.error("[Redis分布式锁] 解锁出现异常了,{}", e); } } } //使用锁的类方法: @Autowired private RedisLock redisLock;//redis锁 //超时时间 private static final int TIMEOUT = 10 * 1000;//超时时间 10s ------------------------------------------------------------ @Override public void orderProductMockDiffUser(String productId) { ************//加锁************ long time = System.currentTimeMillis() + TIMEOUT; if (!redisLock.lock(productId, String.valueOf(time))) { throw new OrderException("", "很抱歉,人太多了,换个姿势再试试~~"); } //1.查询该商品库存,为0则活动结束 int stockNum = stock.get(productId); if (stockNum == 0) { throw new OrderException("", "活动结束"); } else { //2.下单 orders.put(TableIdUtil.tableId(), productId); //3.减库存 stockNum = stockNum - 1;//不做处理的话,高并发下会出现超卖的情况,下单数,大于减库存的情况。 虽然这里减了,但由于并发,减的库存还没存到map中去。新的并发拿到的是原来的库存 try { Thread.sleep(100);//模拟减库存的处理时间 } catch (InterruptedException e) { e.printStackTrace(); } stock.put(productId, stockNum); } ************//解锁************ redisLock.unlock(productId, String.valueOf(time)); }
springboot的核心功能,start的原理
springcloud的网关,其他主要组件
feign等远程调用流程原理